
Spis treści:
- Co to jest atrybucja?
- Heurystyczne modele atrybucji
- Atrybucja w Google Analytics 4
- Atrybucja w modelu Markowa
- Teoria
- Jak przeliczyć atrybucję z surowych danych na łańcuchy Markowa w BigQuery?
- Efekt + porównanie
- Wnioski
Jaki model atrybucji będzie dla mnie najlepszy? Odpowiedź: To zależy. Sprawę „ułatwia” nam w pewien sposób Google, wycofując we wrześniu 2023 z Google Analytics 4 modele heurystyczne i zostawiając tylko 3 modele atrybucji. Powoduje to, że chcąc wykorzystać inne modele, musimy je przeliczyć sami. Dopiero porównując ze sobą dane z różnych modeli, możemy zastanowić się, jaki model atrybucji będzie najlepszy dla naszego biznesu. Jak zatem policzyć atrybucję? Jak porównać dane z różnych modeli między sobą? Sprawdźmy, jak to zrobić korzystając z danych Google Analytics 4 (GA4) i chmury Google – BigQuery.
Co to jest atrybucja?
Atrybucja konwersji to w marketingu proces określania, które działania marketingowe przyczyniły się do pożądanego zachowania klienta np. zakupu produktu, zapisu do newslettera czy wypełnienia formularza kontaktowego.
W zależności, jaki model wybierzemy, wartość i liczba konwersji zostanie przypisana inaczej. Innymi słowy: modele atrybucji przypisują danym źródłom, kanałom, reklamom konkretne wartości, w zależności od wybranej metodologii.
Heurystyczne modele atrybucji
Na podstawie tego, jaki model wykorzystuje dane narzędzie – w taki sposób zostanie podzielona zasługa za konkretne działania. Najbardziej rozpowszechniony do tej pory był model ostatniego niebezpośredniego kliknięcia (tzw. last click a w Google Analytics Universal last not direct click), który wartość i liczbę konwersji przypisuje ostatniemu źródłu (niebezpośredniemu), które ją spowodowało.
Inne modele to heurystyczne to:

Atrybucja w Google Analytics 4
GA4 wprowadza w atrybucji swoistą rewolucję – zapoczątkowaną kilka lat temu w Google Ads. Chodzi o powolne odchodzenie od heurystycznych modeli, na korzyść modeli algorytmicznych. Dzielą one liczbę konwersji i ich wartość na mniejsze części i przypisują je różnym źródłom, które występują na ścieżce użytkownika. GA4 korzysta na ten moment w różnych raportach z 3 modeli atrybucji:
- data driven,
- last not direct click np. w raporcie pozyskanie ruchu,
- first click – np. w raporcie pozyskanie użytkownika.
Model data driven dzieli konwersje na mniejsze części – stąd w raportach możemy zobaczyć konwersje cząstkowe (innymi słowy, wartości po przecinku).
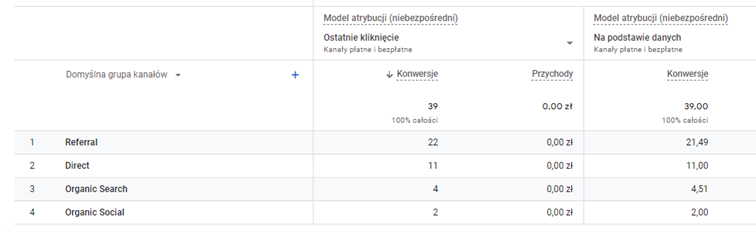
Model data driven, oparty na wartości Shapley’a z teorii gier losowych przypisuje wartości algorytmicznie – jak to się dzieje? Jak ustalane są poszczególne wagi? Możemy o tym przeczytać w pomocy Google:
„Wykorzystuje algorytmy systemów uczących się do oceny zarówno ścieżek konwersji, jak i ścieżek bez konwersji. Powstały w ten sposób model oparty na danych uczy się, w jaki sposób różne punkty kontaktu wpływają na wyniki konwersji. Model uwzględnia takie czynniki, jak czas, który upłynął od konwersji, rodzaj urządzenia, liczba interakcji z reklamą, kolejność ekspozycji na reklamy czy typ komponentów kreacji. Korzystając z metody przeciwstawnej hipotezy, model porównuje ze sobą to, co zaszło z tym, co mogłoby się wydarzyć, aby określić, które punkty kontaktu najprawdopodobniej doprowadzą do konwersji. Model przypisuje tym punktom kontaktu udział w konwersji na podstawie obliczonego prawdopodobieństwa” – źródło tutaj.
Z końcem września zostaną wycofane z Google Analytics 4 modele heurystyczne takie jak liniowy, upływ czasu, uwzględnienie pozycji. Jak przeliczyć atrybucję na inny model niż last click lub data driven? Z pomocą przychodzi BigQuery – hurtownia danych, do której możemy przesłać dane z GA4 i na surowych danych wykonać dowolne operacje.
Atrybucja w modelu Markowa
Alternatywą do algorytmicznego modelu data driven, jest atrybucja oparta na łańcuchach Markowa. W wielu przypadkach lepiej opisuje ona rzeczywistość. Warto sprawdzić, które elementy naszego media mixu, są niedoszacowane, a które są przeszacowane. Modele atrybucji oparte na łańcuchach Markowa nie przyjmują,
że wszystkie kanały marketingowe mają taki sam wpływ na konwersję.
Teoria
Opisywany model, wykorzystuje teorię łańcuchów Markowa, do określania wpływu poszczególnych kanałów marketingowych na konwersję.
W modelu atrybucji opartym na łańcuchach Markowa ścieżka konwersji jest traktowana jako łańcuch Markowa,
w którym stany reprezentują interakcje klienta z marką. Prawdopodobieństwo przejścia z jednego stanu do drugiego zależy od kanału marketingowego, w którym klient wykonał interakcję.
Model atrybucji oparty na łańcuchach Markowa można wykorzystać do przypisania udziału w konwersji do poszczególnych kanałów marketingowych. Udział w konwersji dla danego kanału marketingowego jest obliczany jako prawdopodobieństwo przejścia z poprzedniego stanu do stanu konwersji, przy założeniu, że kanał marketingowy był kanałem, w którym klient wykonał interakcję.
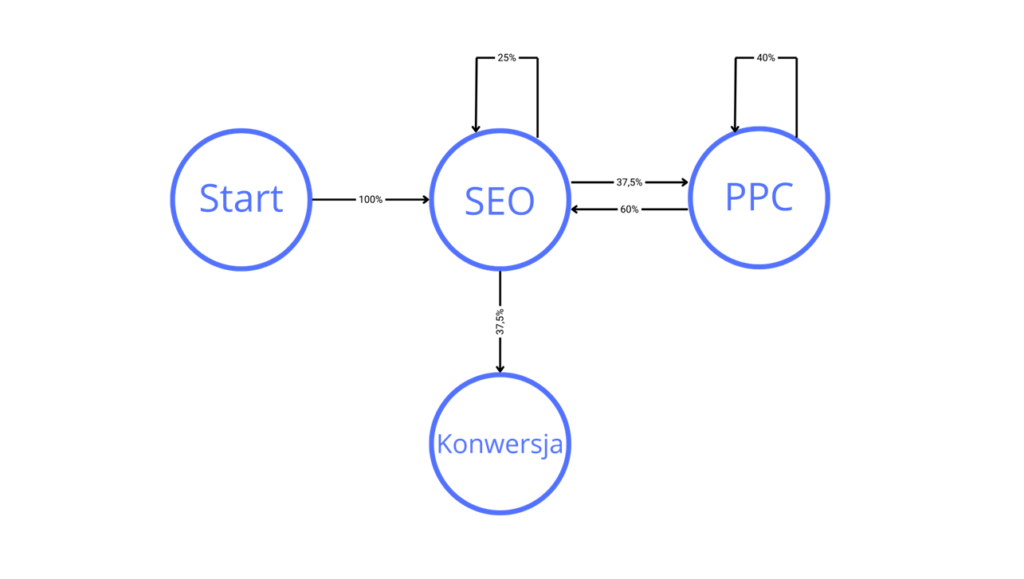
Model atrybucji oparty na łańcuchach Markowa ma kilka zalet, w tym:
- jest bardziej realistyczny niż modele atrybucji oparte heurystycznie,
- jest mniej wrażliwy na przypadkowe dane o małej istotności statystycznej,
- jest mniej obciążający obliczeniowo, dzięki temu możemy rozbijać kanały na subkanały i dokonywać bardziej granularnych obliczeń,
- inaczej niż Model Shapley’a – nie dyskryminuje kanałów domykających na ścieżkach (np. remarketingu).
Jak przeliczyć atrybucję z surowych danych na łańcuchy Markowa w BigQuery?
Czego będziemy potrzebować?
1. Projektu w Google Cloud, w którym przechowamy dane oraz połączonego z nim konta GA4,
2. Środowiska do uruchomienia skryptu w Python,
3. Biblioteki phytonowej: https://github.com/DP6/Marketing-Attribution-Models.
Biblioteka umożliwia nam za pomocą skryptów pyhtonowych i zapytań SQL-owych dokonać skomplikowanych przeliczeń matematycznych, aby z surowych danych, uzyskać wybrany model heurystyczny lub model oparty na łańcuchach Markowa.
4. Odpowiednich danych, które prześlemy do BigQuery. Szczególnie ważne będą:
journey_id: unikalny id ścieżki użytkownika. Najczęściej będzie to kombinacja identyfikatora sesji i użytkownika,
path_channels: kanał ścieżki prowadzący do konwersji,
path_timestamps: różnicę między czasem kliknięcia i konwersji,
conversion: danych o konwersji,
conversion_value: wartość konwersji,
user_pseudo_id : wartość przekazywana do BQ, kombinacja cookie id i identyfikatora sesji,
user_id: unikalny identyfikator użytkownika,
ga_session_id : identyfikator sesji.
5. Skonfigurowanego grupowania kanałów w GA4 – grupowanie kanałów, które dobrze odzwierciedla nasze wydatki marketingowe. Innymi słowy, podziału media mixu na mniejsze części, dla których będziemy chcieli porównać wartości i liczby konwersji.
Za pomocą biblioteki i danych z BigQuery możemy zbudować model, który przeliczy atrybucję z GA4 składowaną
w BigQuery w postaci surowych danych, na atrybucję opartą na Łańcuchach Markowa. Szczegółowe kody pythonowe
i algorytm, znajdziesz w tym artykule.
Efekt + porównanie
Wynikiem wykonanych przeliczeń będzie przypisana przez model liczba transakcji i/lub przychodów, która została przypisana do konkretnego kanału. Wyniki różnych atrybucji możemy śmiało pomiędzy sobą porównywać – pozwoli nam to na lepsze zrozumienie ścieżki użytkownika.
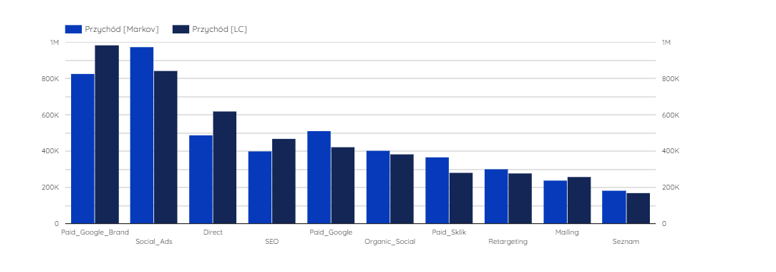
Dla powyższego wykresu możemy zauważyć, że o ile Google w modelu last click zaraportował prawie 1 milion złotych przychodu, to w modelu atrybucji opartej o łańcuchy, wyszło niewiele ponad 800 tysięcy złotych. Z drugiej strony w modelu last click przychody z Social Ads zostały mocno niedoszacowane (ponad 100 000 złotych więcej widzimy w modelu Markowa). W ten sposób możemy później na podstawie takich danych przetestować inny podział budżetów marketingowych.
Wnioski
Analiza różnych modeli atrybucji może pomóc w zrozumieniu, jak klienci przechodzą przez ścieżkę konwersji. Różne modele pomogą nam lepiej estymować zależności między ścieżkami oraz lepiej określić, które z są ważne i wymagają dofinansowania, a z których możemy zwyczajnie zrezygnować.
Jeżeli potrzebujesz pomocy w przeliczaniu, konfiguracji BigQuery – zapraszamy do kontaktu.
Źródła:
- https://support.google.com/analytics/answer/10596866?hl=pl&sjid=10004842146549516972-EU#zippy=%2Cin-this-article%2Cthe-methodology-behind-data-driven-attribution-advanced%2Ctematy-w-tym-artykule%2Cmetodologia-atrybucji-opartej-na-danych-zaawansowana
- https://sprawnymarketing.pl/blog/wartosc-shapleya-w-modelowaniu-atrybucji/
- https://towardsdatascience.com/brief-introduction-to-markov-chains-2c8cab9c98ab
- https://stacktonic.com/article/build-a-data-driven-attribution-model-using-google-analytics-4-big-query-and-python

